Recently we’ve given you an update on Ellie’s future roadmap, where we’ve gone through our upcoming features and shared the product vision. In this post, we want to explore the technological shifts that define why we’re building Ellie in a certain way. Here are, what we believe, the four data megatrends that will have a big impact on the future of the data industry and thus on our product development.
The listing of the cloud company Snowflake a couple of years ago was the largest in the software industry. The benefits of applications delivered as a cloud service are simply overwhelming: automatic updates, version control, affordability, and deployment speed are some of the good examples. The largest companies in the cloud platform industry, Microsoft Azure, AWS, and Google Cloud Platform, are the largest companies in the world, precisely because of the benefits mentioned above.
An increasing proportion of enterprise software moves to the cloud – this development can no longer be changed. Sure, there will always be on-premise solutions, but they’ll be completely marginalized in the big picture. “On-prems” are required by some regulated industries, such as security, banking, and healthcare. That, too, is only due to the fact that the regulations were made sometime before the cloud.
A classic example is to suggest that “on-prem” would be a more secure solution. This is simply not the case. Platform vendors are investing thousands of times more in security than, say, a big international bank.
This is exactly why we’re building Ellie to be a high-security cloud-based product meaning it’s built directly into the cloud and delivered with a SaaS model.
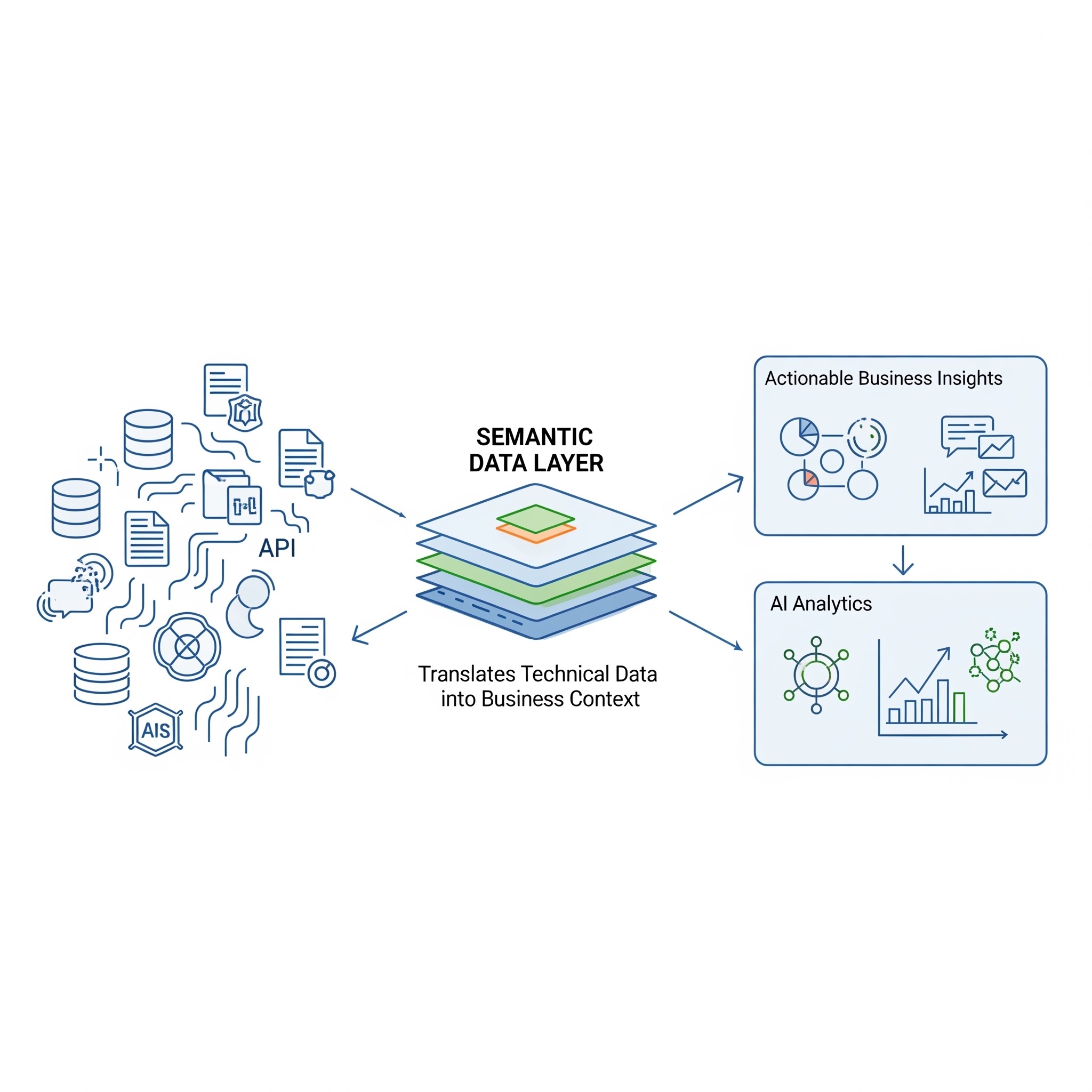
Collibra is a widely used data catalog product. Its value rose to 5.5 billion after the last round of funding. Its founders once saw that one of the big problems with the data scene is the fragmentation of data storage locations – many organizations have hundreds of software and IT systems and have no clue where the data ends up. However, many of our customers have encountered a particular challenge with data catalogs.
Yes, data catalogs can list the data lineage, which means that you can determine where the data is generated. They can also be used to do an inventory of datasets and find out where in the database the table is located. The challenge is that the lists of attributes do not yet tell the context of the data, even though it is very relevant.
It’s the same when you have a neat phone book in your hands, but no one would tell you that these are, in fact, people’s phone numbers. Without this information, it’s just a “list” of people’s names followed by some strange series of numbers.
At Ellie, we believe that one big challenge will be understanding data and combining business with technical information. Business concepts such as customer, product, and billing are not separate “objects”, and almost always the utilization of the data should start with finding out the relationships between them.
For example, how many patients are discharged from hospital care, or how many leads are converted into a sale?
As you can see, it’s always about the relationship between things. Understanding data is precisely about context and how things relate to each other. There is no ‘customer’ without billing or delivery. Context is everything!
Because of this interesting trend, we’re aiming to create native integrations of Ellie with data catalogs – allowing users to better understand the semantics of data with the tools they already use.


The advantage of Ellie is its excellent UI / UX, it is intuitive and easy to use compared to legacy, desktop-only, software. This is important, as it’s directly related to a long-standing IT trend, where in order for a technology to be widely used across an organization, it should be easily approachable by anyone, including non-technical users.
The data industry is currently plagued by a certain gap between business and data experts. It is thought that business is not a part of it and the definition of requirements for a data project is only done as an internal IT task.
This approach is going away, however, as data development must have a clear benefit to the business operations, like increasing revenue or saved costs, and the product teams must be involved in the data projects. Of course, the IT and data teams cannot force business departments into this shift, meaning that the IT organization alone cannot solve this, but the top management of the company can.
In cloud services, software development was ahead of the data industry and was the first one to move to the cloud, later, the data industry followed. Similarly, there has long been a trend in software development for product and business goals to drive the development, and not the other way around. Here, too, the data industry will follow software development, which means business-driven data projects will be one megatrend in the coming years.
Distributed architecture is an integral part of the much-hyped trend of Data Mesh. In technical terms, this means API architecture, micro-services, and the transition away from large monolithic IT systems.
The other half of the coin is the organizational structure. This has a lot to do with the previously mentioned trend where business teams are starting to approach data development.
Today, the situation for many is that there is a centralized data team that acts like an “internal consulting firm,” providing services to different business departments and domains. The challenge, however, is that they have no way of understanding all areas of business or how data is generated within them.
Therefore, there is now a growing adoption of frameworks where each unit has its own data experts and developers. This does not mean that centralized data infrastructure is not needed at all – on the contrary.
If you use the analogy of water pipes, then a centralized data team will make sure that the pipes are in good condition and the water flows through them for all who need it.
The fact that drinkable water flows in the pipes, and not wastewater, for example, is the responsibility of the business operations.
This trend will have perhaps the biggest impact on Ellie’s development, as maintaining the cross-domain “mesh” will be the biggest challenge of them all.
Predictions are always easy to make because no one has visited the future and doesn’t know what will actually happen.
However, it is relatively certain that the data industry will grow well into the future. Data Engineering skills are perhaps the most sought-after skills today and the industry is evolving at a rapid pace. The need for data management and architecture skills rises in the same proportion: the more data engineers build the pipelines (the more difficulty there is in the hybrid, on-premise, and cloud platforming), the more someone has to maintain the data stack – the bigger the risk of duplication of work or point-by-point solutions in the absence of clear coordination.
This increased demand for data usage creates a requirement of adopting new tools and frameworks that can be used to tackle the challenges of modern data needs.